Built a document intelligence platform to solve a real problem on our team, then open-sourced it as a one-click Railway template so any team could deploy it in minutes.
I was deep into the design strategy across a large enterprise program spanning multiple workstreams. The output was substantial: analysis documents, gap trackers, blueprint decks, and strategy write-ups, all living in a GitHub repo. Sensitive internal documents that couldn't be sent to third-party AI services.
The problem was simple: nobody could find anything. Stakeholders would ask "what's the status of the onboarding workflows?" and the answer required opening five different .docx files, cross-referencing an Excel tracker, and remembering which decisions had been made three months ago. Every question meant a manual scavenger hunt. I watched our team burn hours every week just locating information we'd already produced.
This wasn't assigned work. Nobody filed a ticket or raised it in a retro. I spotted the pattern: every meeting started with someone digging through files, every status update required re-reading documents we'd already written, and every new team member faced a weeks-long ramp just to understand what had been decided. I recognized that as a systemic problem, not just an inconvenience, and took it on myself to solve it. The goal was to give our team back the hours we were burning on document archaeology so we could spend them on the actual strategy work. And because these were sensitive internal documents, whatever I built had to keep everything local. No external APIs. No data leaving the machine.
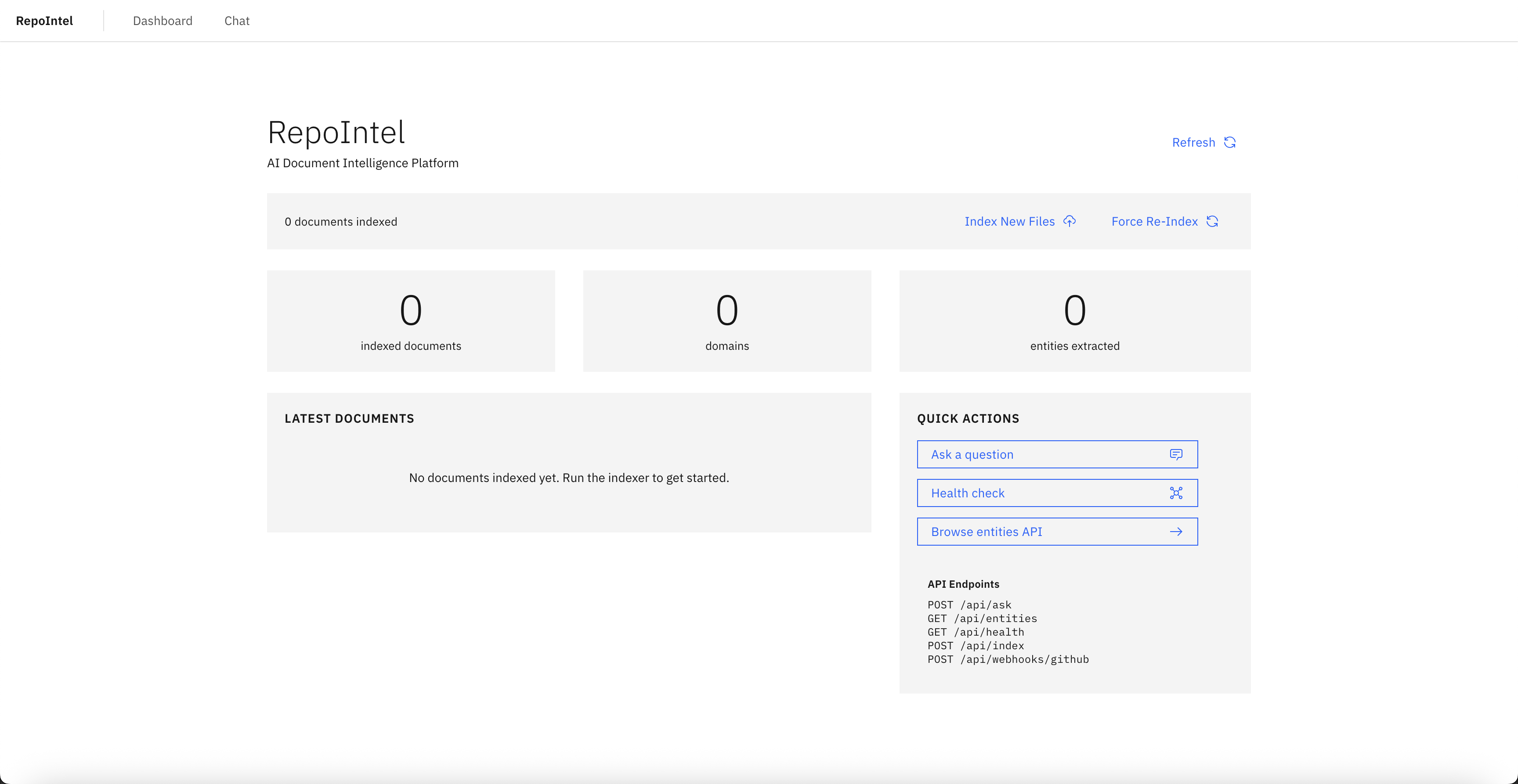
The first version was called Recall, an internal tool built for a specific enterprise program. It indexed workflow documents from GitHub, extracted entities (decisions, dependencies, gaps, stakeholders, milestones, workflows), mapped relationships between them, and gave the team a RAG-powered chat interface to ask questions with source citations. Everything ran locally. Ollama handled embeddings and chat inside the container. No data left the machine. No API keys needed. For a team working with sensitive internal documents, this wasn't a nice-to-have, it was a requirement.
It worked. Questions that took 20 minutes of document diving now took 10 seconds. But I realized the problem wasn't unique to our team. Every program with a document corpus has the same findability gap and the same privacy concerns about sending proprietary documents to external AI services. So I rebuilt Recall as RepoIntel, a generalized, open-source version that any team could deploy against their own GitHub repo with the same local-first privacy guarantees.
The key design decision: ship it as a Railway template. One click, environment variables configured, and you have a running instance indexing your repo. No Docker knowledge required. No infrastructure setup. No API keys. The gap between "I have documents" and "I have intelligence" should be measured in minutes, not sprints.
Leading this effort. No one asked for RepoIntel. I identified the findability and privacy problem firsthand on an enterprise engagement, built the internal tool (Recall) to enable my team, then generalized and open-sourced it so other teams with the same constraints could skip the custom build. Solo build end to end, scoped so it could be adopted by teams I'd never meet.
The UI is built with IBM's Carbon Design System. Each view serves a different mode of interaction: browsing (Dashboard), asking (Chat), tracking (Gap Tracker), and monitoring (Risk Radar). They all read from the same locally-stored indexed data, so a gap surfaced in chat is the same gap tracked in the Gap Tracker and scored in the Risk Radar. No external services are called at any point in the user flow.
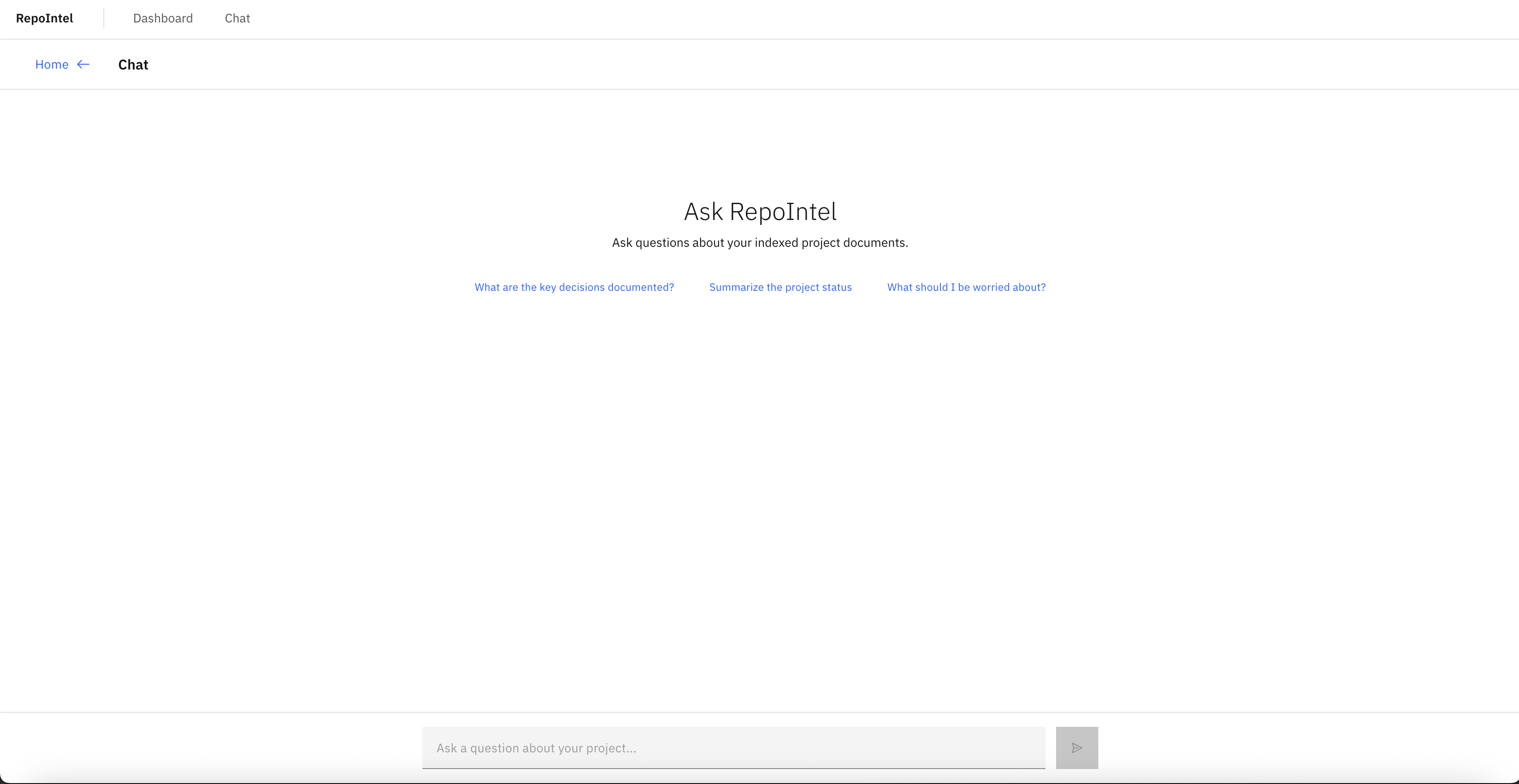
RepoIntel started as a tool to solve my team's problem. But the pattern it solves, turning a pile of documents into searchable, structured intelligence without sending anything to a third party, is universal. Every consulting engagement, every enterprise program, every legal team has a document corpus that's both hard to navigate and too sensitive for external AI tools.
Open-sourcing it as a one-click Railway template was a deliberate decision. The deployment barrier had to be zero. No Docker knowledge, no infrastructure provisioning, no config files to edit. Click deploy, add your GitHub token and repo, and you have a running instance in under 5 minutes. Your data stays on your Railway instance.
The template packages everything into a single container: Next.js for the app, Ollama for local embeddings and chat (zero API keys required by default), ChromaDB for vector storage, and SQLite for structured data. Railway's persistent volume means your index survives redeploys. The entire AI stack runs inside the container, so document content never touches an external server.
Recall replaced the weekly document scavenger hunts that were eating hours of the team's time. Questions that required opening five files and cross-referencing a tracker now got answered in seconds through RAG chat with source citations. New team members stopped needing weeks to ramp up on past decisions because the entire knowledge base was searchable from day one.
When RepoIntel launched as an open-source Railway template, the same architecture became available to any team with a GitHub repo and sensitive documents. The one-click deploy model meant teams could go from "I have a document problem" to "I have a running intelligence platform" in under five minutes, with zero data leaving their infrastructure.